
【面试】后端面试题集01
🍦 关于整型切⽚的初始化,下⾯正确的是?
- A. s := make([]int)
- B. s := make([]int, 0)
- C. s := make([]int, 5, 10)
- D. s := []int{1, 2, 3, 4, 5}
🍧 下列代码是否会触发异常?
| |
🍨 关于channel的特性,下⾯说法正确的是?
- A. 给⼀个 nil channel 发送数据,造成永远阻塞
- B. 从⼀个 nil channel 接收数据,造成永远阻塞
- C. 给⼀个已经关闭的 channel 发送数据,引起 panic
- D. 从⼀个已经关闭的 channel 接收数据,如果缓冲区中为空,则返回⼀个零值
🍩 下列代码有什么问题?
| |
🍪 下列代码输出什么?
| |
🎂 关于⽆缓冲和有冲突的channel,下⾯说法正确的是?
- A. ⽆缓冲的channel是默认的缓冲为1的channel;
- B. ⽆缓冲的channel和有缓冲的channel都是同步的;
- C. ⽆缓冲的channel和有缓冲的channel都是⾮同步的;
- D. ⽆缓冲的channel是同步的,⽽有缓冲的channel是⾮同步的;
🍰 下列代码输出什么?
| |
🧁 关于select机制,下⾯说法正确的是?
- A. select机制⽤来处理异步IO问题;
- B. select机制最⼤的⼀条限制就是每个case语句⾥必须是⼀个IO操作;
- C. golang在语⾔级别⽀持select关键字;
- D. select关键字的⽤法与switch语句⾮常类似,后⾯要带判断条件;
🥧 关于字符串拼接,下列正确的是?
- A. str := ‘abc’ + ‘123’
- B. str := “abc” + “123”
- C. str := ‘123’ + “abc”
- D. fmt.Sprintf(“abc%d”, 123)
🍫 连nil切⽚和空切⽚⼀不⼀样都不清楚?
连nil切片和空切片一不一样都不清楚?那BAT面试官只好让你回去等通知了。
🍬 golang⾯试题:字符串转成byte数组,会发⽣内存拷⻉吗?
golang⾯试题:字符串转成byte数组,会发⽣内存拷⻉吗?
🍭 golang⾯试题:翻转含有中⽂、数字、英⽂字⺟的字符串
🍮 golang⾯试题:拷⻉⼤切⽚⼀定⽐⼩切⽚代价⼤吗?
🍯 golang⾯试题:json包变量不加tag会怎么样?
🍼 golang⾯试题:reflect(反射包)如何获取字段tag?为什么json包不能导出私有变量的tag?
golang⾯试题:reflect(反射包)如何获取字段tag?为什么json包不能导出私有变量的tag?
🥛 昨天那个在for循环⾥append元素的同事,今天还在么?
☕ go struct能不能⽐较
🍵 Go ⽀持什么形式的类型转换?将整数转换为浮点数。
🍶 Log包线程安全吗?
🍾 Goroutine和线程的区别?
展开查看详情
从调度上看,goroutine的调度开销远远⼩于线程调度开销。
OS的线程由OS内核调度,每隔⼏毫秒,⼀个硬件时钟中断发到CPU,CPU调⽤⼀个调度器内核函数。这个函数暂停当前正在运⾏的线程,把他的寄存器信息保存到内存中,查看线程列表并决定接下来运⾏哪⼀个线程,再从内存中恢复线程的注册表信息,最后继续执⾏选中的线程。这种线程切换需要⼀个完整的上下⽂切换:即保存⼀个线程的状态到内存,再恢复另外⼀个线程的状态,最后更新调度器的数据结构。某种意义上,这种操作还是很慢的。
Go运⾏的时候包涵⼀个⾃⼰的调度器,这个调度器使⽤⼀个称为⼀个M:N调度技术,m个goroutine到n个os线程(可以⽤GOMAXPROCS来控制n的数量),Go的调度器不是由硬件时钟来定期触发的,⽽是由特定的go语⾔结构来触发的,他不需要切换到内核语境,所以调度⼀个goroutine⽐调度⼀个线程的成本低很多。
从栈空间上,goroutine的栈空间更加动态灵活。
每个OS的线程都有⼀个固定⼤⼩的栈内存,通常是2MB,栈内存⽤于保存在其他函数调⽤期间哪些正在执⾏或者临时暂停的函数的局部变量。这个固定的栈⼤⼩,如果对于goroutine来说,可能是⼀种巨⼤的浪费。作为对⽐goroutine在⽣命周期开始只有⼀个很⼩的栈,典型情况是2KB, 在go程序中,⼀次创建⼗万左右的goroutine也不罕⻅(2KB*100,000=200MB)。⽽且goroutine的栈不是固定⼤⼩,它可以按需增⼤和缩⼩,最⼤限制可以到1GB。
goroutine没有⼀个特定的标识。
在⼤部分⽀持多线程的操作系统和编程语⾔中,线程有⼀个独特的标识,通常是⼀个整数或者指针,这个特性可以让我们构建⼀个线程的局部存储,本质是⼀个全局的map,以线程的标识作为键,这样每个线程可以独⽴使⽤这个map存储和获取值,不受其他线程⼲扰。
goroutine中没有可供程序员访问的标识,原因是⼀种纯函数的理念,不希望滥⽤线程局部存储导致⼀个不健康的超距作⽤,即函数的⾏为不仅取决于它的参数,还取决于运⾏它的线程标识。
🍷下列哪⼀⾏会panic?
| |
🍷 下列哪⾏代码会panic?
| |
🍸 什么是 Goroutine?你如何停⽌它?
展开查看详情
⼀个 Goroutine 是⼀个函数或⽅法执⾏同时旁边其他任何够程采⽤了特殊的 Goroutine 线程。Goroutine 线程⽐标准线程更轻量级,⼤多数 Golang 程序同时使⽤数千个 g、Goroutine。
要创建 Goroutine,请 go 在函数声明之前添加go关键字。
您可以通过向 Goroutine 发送⼀个信号通道来停⽌它。Goroutines 只能在被告知检查时响应信号,因此您需要在逻辑位置(例如 for 循环顶部)包含检查。
| |
🍹 Golang中除了加Mutex锁以外还有哪些⽅式安全读写共享变量?
🍺 ⽆缓冲 Chan 的发送和接收是否同步?
🍺 关于switch语句,下⾯说法正确的有?
- A. 条件表达式必须为常量或者整数;
- B. 单个case中,可以出现多个结果选项;
- C. 需要⽤break来明确退出⼀个case;
- D. 只有在case中明确添加fallthrough关键字,才会继续执⾏紧跟的下⼀个case;
🥃 下列Add函数定义正确的是?
| |
🥤 关于 bool 变量 b 的赋值,下⾯错误的⽤法是?
- A. b = true
- B. b = 1
- C. b = bool(1)
- D. b = (1 == 2)
🧃 关于变量的⾃增和⾃减操作,下⾯语句正确的是?
A.
| |
B.
| |
C.
| |
D.
| |
🧉 go语⾔的并发机制以及它所使⽤的CSP并发模型.
展开查看详情
CSP模型是上个世纪七⼗年代提出的,不同于传统的多线程通过共享内存来通信,CSP讲究的是“以通信的⽅式来共享内存”。⽤于描述两个独⽴的并发实体通过共享的通讯 channel(管道)进⾏通信的并发模型。 CSP中channel是第⼀类对象,它不关注发送消息的实体,⽽关注与发送消息时使⽤的channel。
Golang中channel 是被单独创建并且可以在进程之间传递,它的通信模式类似于 boss-worker 模式的,⼀个实体通过将消息发送到channel 中,然后⼜监听这个 channel 的实体处理,两个实体之间是匿名的,这个就实现实体中间的解耦,其中 channel 是同步的⼀个消息被发送到 channel 中,最终是⼀定要被另外的实体消费掉的,在实现原理上其实类似⼀个阻塞的消息队列。
Goroutine 是Golang实际并发执⾏的实体,它底层是使⽤协程(coroutine)实现并发,coroutine是⼀种运⾏在⽤户态的⽤户线程,类似于 greenthread,go底层选择使⽤coroutine的出发点是因为,它具有以下特点:
- ⽤户空间 避免了内核态和⽤户态的切换导致的成本。
- 可以由语⾔和框架层进⾏调度。
- 更⼩的栈空间允许创建⼤量的实例。
Golang中的Goroutine的特性:
Golang内部有三个对象: P对象(processor) 代表上下⽂(或者可以认为是cpu),M(work thread)代表⼯作线程,G对象(goroutine).
正常情况下⼀个cpu对象启⼀个⼯作线程对象,线程去检查并执⾏goroutine对象。碰到goroutine对象阻塞的时候,会启动⼀个新的⼯作线程,以充分利⽤cpu资源。 所有有时候线程对象会⽐处理器对象多很多.
我们⽤如下图分别表示P、M、G:
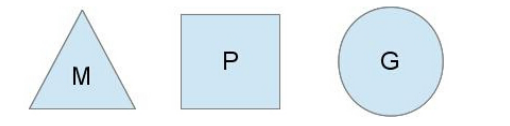
G(Goroutine) :我们所说的协程,为⽤户级的轻量级线程,每个Goroutine对象中的sched保存着其上下⽂信息.
M(Machine) :对内核级线程的封装,数量对应真实的CPU数(真正⼲活的对象).
P(Processor) :即为G和M的调度对象,⽤来调度G和M之间的关联关系,其数量可通过GOMAXPROC()来设置,默认为核⼼数.
在单核情况下,所有Goroutine运⾏在同⼀个线程(M0)中,每⼀个线程维护⼀个上下⽂(P),任何时刻,⼀个上下⽂中只有⼀个Goroutine,其他Goroutine在runqueue中等待。
⼀个Goroutine运⾏完⾃⼰的时间⽚后,让出上下⽂,⾃⼰回到runqueue中(如下图所示)。 当正在运⾏的G0阻塞的时候(可以需要IO),会再创建⼀个线程(M1),P转到新的线程中去运⾏。
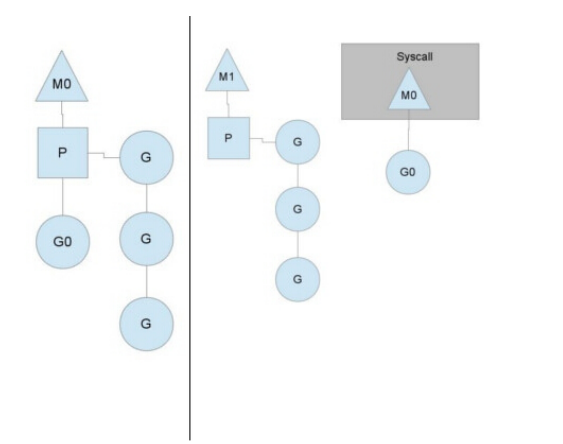
当M0返回时,它会尝试从其他线程中“偷”⼀个上下⽂过来,如果没有偷到,会把Goroutine放到Global runqueue中去,然后把⾃⼰放⼊线程缓存中。 上下⽂会定时检查Global runqueue。
Golang是为并发⽽⽣的语⾔,Go语⾔是为数不多的在语⾔层⾯实现并发的语⾔;也正是Go语⾔的并发特性,吸引了全球⽆数的开发者。
Golang的CSP并发模型,是通过Goroutine和Channel来实现的。
Goroutine 是Go语⾔中并发的执⾏单位。有点抽象,其实就是和传统概念上的”线程“类似,可以理解为”线程“。Channel是Go语⾔中各个并发结构体(Goroutine)之前的通信机制。通常Channel,是各个Goroutine之间通信的”管道“,有点类似于Linux中的管道。
通信机制channel也很⽅便,传数据⽤channel <- data,取数据⽤<-channel。在通信过程中,传数据channel <- data和取数据<-channel必然会成对出现,因为这边传,那边取,两个goroutine之间才会实现通信。
⽽且不管传还是取,必阻塞,直到另外的goroutine传或者取为⽌。
🧊 Golang 中常⽤的并发模型?
展开查看详情
Golang 中常⽤的并发模型有三种:
- 通过channel通知实现并发控制
⽆缓冲的通道指的是通道的⼤⼩为0,也就是说,这种类型的通道在接收前没有能⼒保存任何值,它要求发送goroutine 和接收 goroutine 同时准备好,才可以完成发送和接收操作。
从上⾯⽆缓冲的通道定义来看,发送 goroutine 和接收 gouroutine 必须是同步的,同时准备后,如果没有同时准备好的话,先执⾏的操作就会阻塞等待,直到另⼀个相对应的操作准备好为⽌。这种⽆缓冲的通道我们也称之为同步通道。
| |
当主 goroutine 运⾏到 <-ch 接受 channel 的值的时候,如果该 channel 中没有数据,就会⼀直阻塞等待,直到有值。 这样就可以简单实现并发控制
- 通过sync包中的WaitGroup实现并发控制
Goroutine是异步执⾏的,有的时候为了防⽌在结束mian函数的时候结束掉Goroutine,所以需要同步等待,这个时候就需要⽤ WaitGroup了,在 sync 包中,提供了 WaitGroup ,它会等待它收集的所有 goroutine 任务全部完成。在WaitGroup⾥主要有三个⽅法:
- Add, 可以添加或减少 goroutine的数量.
- Done, 相当于Add(-1).
- Wait, 执⾏后会堵塞主线程,直到WaitGroup ⾥的值减⾄0.
在主 goroutine 中 Add(delta int) 索要等待goroutine 的数量。 在每⼀个 goroutine 完成后 Done() 表示这⼀个goroutine 已经完成,当所有的 goroutine 都完成后,在主 goroutine 中 WaitGroup 返回返回。
| |
在Golang官⽹中对于WaitGroup介绍是 A WaitGroup must not be copied after first use ,在 WaitGroup第⼀次使⽤后,不能被拷⻉
应⽤示例:
| |
运⾏:
| |
它提示所有的 goroutine 都已经睡眠了,出现了死锁。这是因为 wg 给拷⻉传递到了 goroutine 中,导致只有 Add操作,其实 Done操作是在 wg 的副本执⾏的。
因此 Wait 就死锁了。
这个第⼀个修改⽅式:将匿名函数中 wg 的传⼊类型改为 *sync.WaitGrou,这样就能引⽤到正确的WaitGroup了。 这个第⼆个修改⽅式:将匿名函数中的 wg 的传⼊参数去掉,因为Go⽀持闭包类型,在匿名函数中可以直接使⽤外⾯的 wg 变量
- 在Go 1.7 以后引进的强⼤的Context上下⽂,实现并发控制
通常,在⼀些简单场景下使⽤ channel 和 WaitGroup 已经⾜够了,但是当⾯临⼀些复杂多变的⽹络并发场景下channel 和 WaitGroup 显得有些⼒不从⼼了。 ⽐如⼀个⽹络请求 Request,每个 Request 都需要开启⼀个goroutine 做⼀些事情,这些 goroutine ⼜可能会开启其他的 goroutine,⽐如数据库和RPC服务。 所以我们需要⼀种可以跟踪 goroutine 的⽅案,才可以达到控制他们的⽬的,这就是Go语⾔为我们提供的 Context,称之为上下⽂⾮常贴切,它就是goroutine 的上下⽂。 它是包括⼀个程序的运⾏环境、现场和快照等。每个程序要运⾏时,都需要知道当前程序的运⾏状态,通常Go 将这些封装在⼀个 Context ⾥,再将它传给要执⾏的 goroutine 。
context 包主要是⽤来处理多个 goroutine 之间共享数据,及多个 goroutine 的管理。
context 包的核⼼是 struct Context,接⼝声明如下:
| |
Done() 返回⼀个只能接受数据的channel类型,当该context关闭或者超时时间到了的时候,该channel就会有⼀个取消信号
Err() 在Done() 之后,返回context 取消的原因。
Deadline() 设置该context cancel的时间点
Value() ⽅法允许 Context 对象携带request作⽤域的数据,该数据必须是线程安全的。
Context 对象是线程安全的,你可以把⼀个 Context 对象传递给任意个数的 gorotuine,对它执⾏ 取消 操作时,所有 goroutine 都会接收到取消信号。
⼀个 Context 不能拥有 Cancel ⽅法,同时我们也只能 Done channel 接收数据。 其中的原因是⼀致的:接收取消信号的函数和发送信号的函数通常不是⼀个。 典型的场景是:⽗操作为⼦操作操作启动 goroutine,⼦操作也就不能取消⽗操作。
🫖 JSON 标准库对 nil slice 和 空 slice 的处理是⼀致的吗?
展开查看详情
⾸先JSON 标准库对 nil slice 和 空 slice 的处理是不⼀致.
通常错误的⽤法,会报数组越界的错误,因为只是声明了slice,却没有给实例化的对象。
| |
此时slice的值是nil,这种情况可以⽤于需要返回slice的函数,当函数出现异常的时候,保证函数依然会有nil的返回值。
empty slice 是指slice不为nil,但是slice没有值,slice的底层的空间是空的,此时的定义下:
| |
当我们查询或者处理⼀个空的列表的时候,这⾮常有⽤,它会告诉我们返回的是⼀个列表,但是列表内没有任何值。
总之,nil slice 和 empty slice是不同的东⻄,需要我们加以区分的.
🧋 协程,线程,进程的区别。
- A. 协程和线程都可以实现程序的并发执⾏;
- B. 线程⽐协程更轻量级;
- C. 协程不存在死锁问题;
- D. 通过 channel 来进⾏协程间的通信;
🎃 互斥锁,读写锁,死锁问题是怎么解决。
展开查看详情
互斥锁
互斥锁就是互斥变量mutex,⽤来锁住临界区的.
条件锁就是条件变量,当进程的某些资源要求不满⾜时就进⼊休眠,也就是锁住了。当资源被分配到了,条件锁打开,进程继续运⾏;读写锁,也类似,⽤于缓冲区等临界资源能互斥访问的。
读写锁
通常有些公共数据修改的机会很少,但其读的机会很多。并且在读的过程中会伴随着查找,给这种代码加锁会降低我们的程序效率。读写锁可以解决这个问题。
| 当前锁的状态 | 读锁请求 | 写锁的请求 |
|---|---|---|
| 无锁 | 可以 | 可以 |
| 读锁 | 可以 | 阻塞 |
| 写锁 | 阻塞 | 阻塞 |
注意:写独占,读共享,写锁优先级⾼
死锁
⼀般情况下,如果同⼀个线程先后两次调⽤lock,在第⼆次调⽤时,由于锁已经被占⽤,该线程会挂起等待别的线程释放锁,然⽽锁正是被⾃⼰占⽤着的,该线程⼜被挂起⽽没有机会释放锁,因此就永远处于挂起等待状态了,这叫做死锁(Deadlock)。 另外⼀种情况是:若线程A获得了锁1,线程B获得了锁2,这时线程A调⽤lock试图获得锁2,结果是需要挂起等待线程B释放锁2,⽽这时线程B也调⽤lock试图获得锁1,结果是需要挂起等待线程A释放锁1,于是线程A和B都永远处于挂起状态了。
死锁产⽣的四个必要条件:
- 互斥条件:⼀个资源每次只能被⼀个进程使⽤
- 请求与保持条件:⼀个进程因请求资源⽽阻塞时,对已获得的资源保持不放。
- 不剥夺条件:进程已获得的资源,在末使⽤完之前,不能强⾏剥夺。
- 循环等待条件:若⼲进程之间形成⼀种头尾相接的循环等待资源关系。 这四个条件是死锁的必要条件,只要系统发⽣死锁,这些条件必然成⽴,⽽只要上述条件之⼀不满⾜,就不会发⽣死锁。
预防死锁
可以把资源⼀次性分配:(破坏请求和保持条件)
然后剥夺资源:即当某进程新的资源未满⾜时,释放已占有的资源(破坏不可剥夺条件)资源有序分配法:系统给每类资源赋予⼀个编号,每⼀个进程按编号递增的顺序请求资源,释放则相反(破坏环路等待条件)
避免死锁
预防死锁的⼏种策略,会严重地损害系统性能。因此在避免死锁时,要施加较弱的限制,从⽽获得 较满意的系统性能。由于在避免死锁的策略中,允许进程动态地申请资源。因⽽,系统在进⾏资源分配之前预先计算资源分配的安全性。若此次分配不会导致系统进⼊不安全状态,则将资源分配给进程;否则,进程等待。其中最具有代表性的避免死锁算法是银⾏家算法。
检测死锁
⾸先为每个进程和每个资源指定⼀个唯⼀的号码,然后建⽴资源分配表和进程等待表.
解除死锁
当发现有进程死锁后,便应⽴即把它从死锁状态中解脱出来,常采⽤的⽅法有.
剥夺资源
从其它进程剥夺⾜够数量的资源给死锁进程,以解除死锁状态.
撤消进程
可以直接撤消死锁进程或撤消代价最⼩的进程,直⾄有⾜够的资源可⽤,死锁状态.消除为⽌.所谓代价是指优先级、运⾏代价、进程的重要性和价值等。